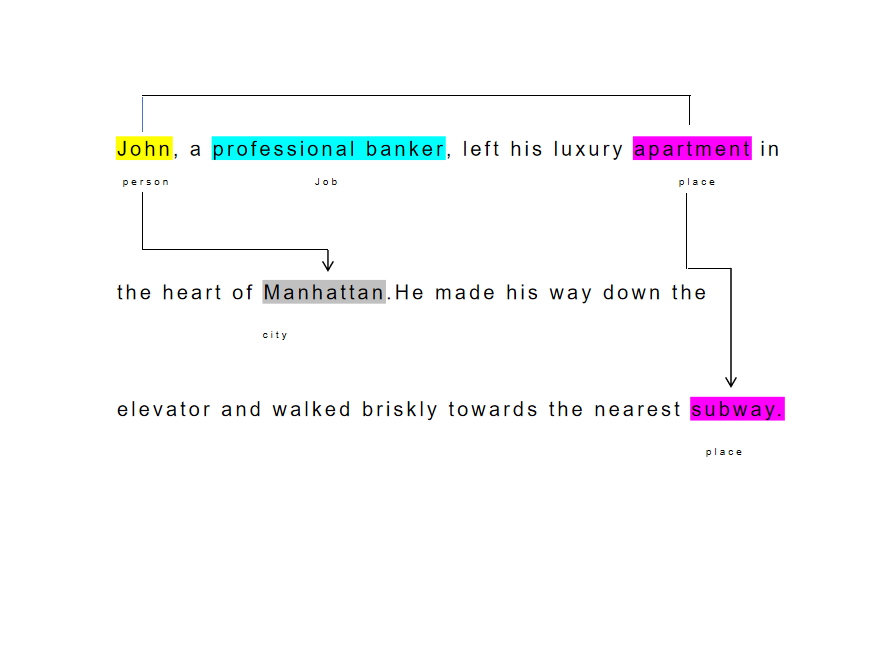
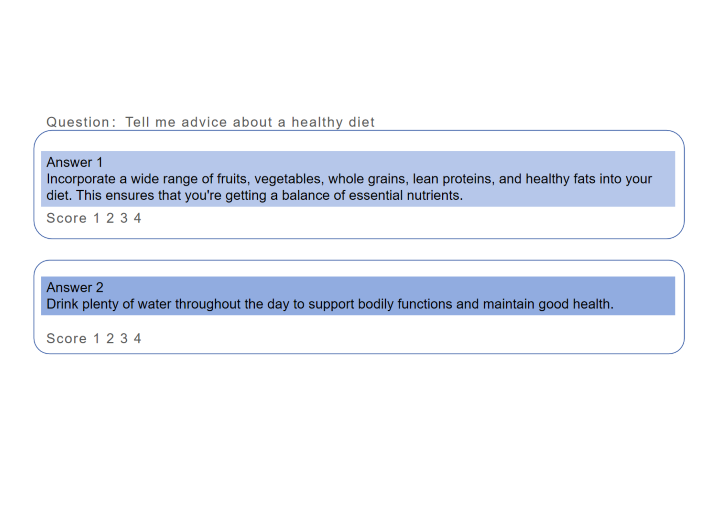
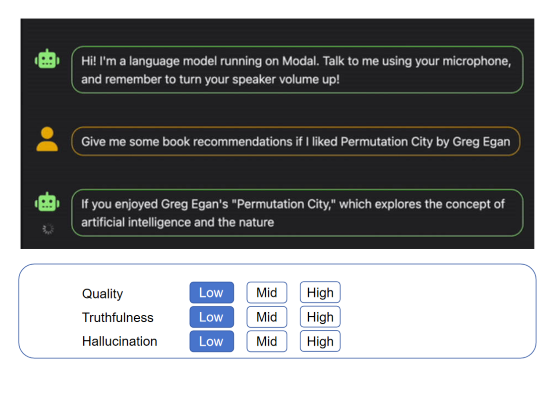
Data cleaning and Extraction
Get clean, high-quality data where issues like missing or inconsistent entries, duplicates, and irrelevant information are identified and rectified. Extract meaningful structured information, such as entities, attributes, relationships, and events, from unstructured or semi-structured text. Benefit from data that's converted into a format optimized for storage, retrieval, and analysis, thereby uncovering hidden knowledge and patterns within your text.